快速排序
问题一:partition
给定一个数组$arr$, 和一个数$num$,请把小于等于$num$的数放在数组的左边,大于$num$的数放在数组的右边。
要求额外空间复杂度 $O(1)$ , 时间复杂度$O(N)$;
解决答案
问题二:荷兰国旗问题
给定一个数组$arr$, 和一个数$num$,请把小于等于$num$的数放在数组的左边,等于$num$的数放在中间,大于$num$的数放在数组的右边。
要求额外空间复杂度 $O(1)$ , 时间复杂度$O(N)$;
解决答案
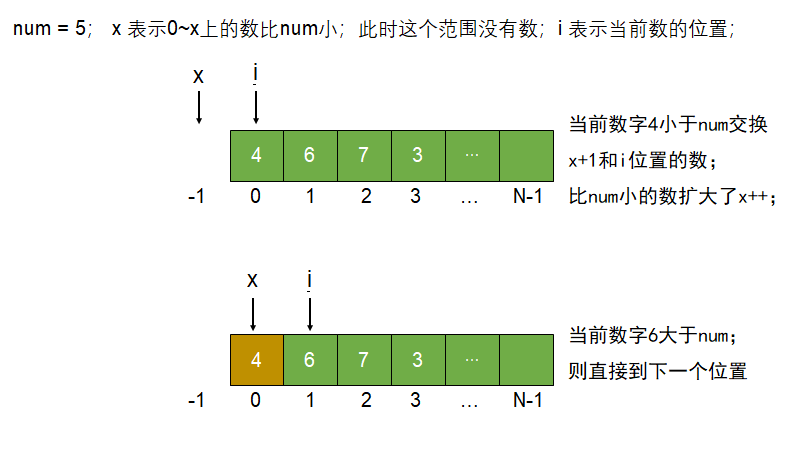
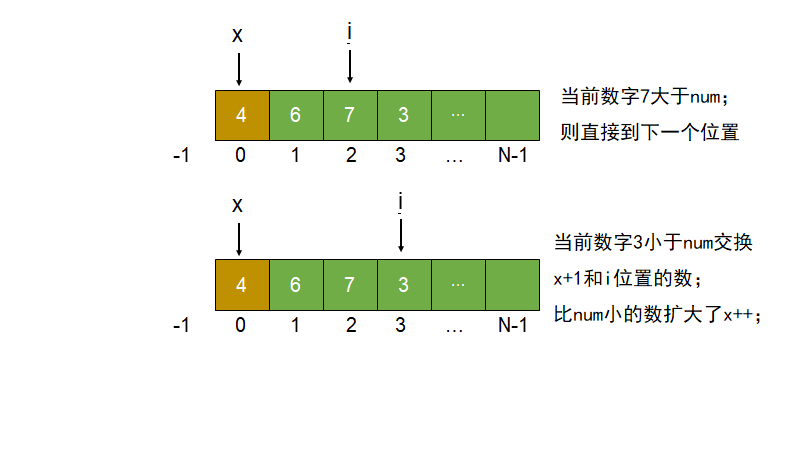
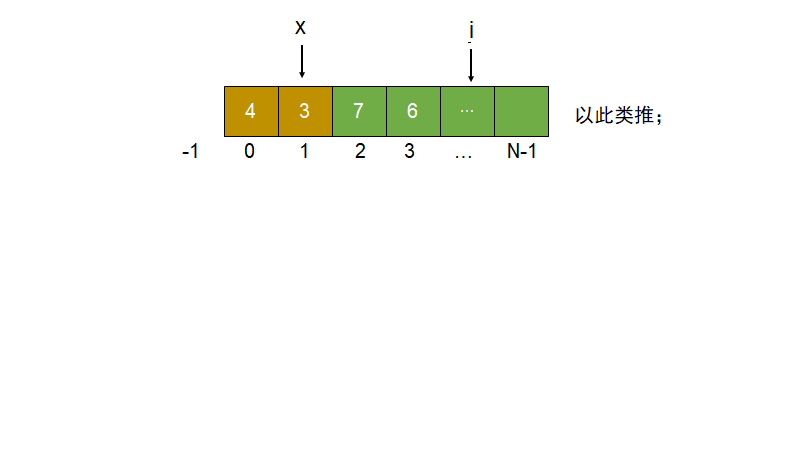
三个变量$less$, $cur$ 和 $more$;
$less$ 表示 $0$ ~ $less $为小于$num$的区域;初始为 -1;
$cur$ 表示 当前判断的数在数组的下标;初始为0;并且 0 ~ $cur$的数组区域都是小于等于$num$的值;
$more$ 表示 $more$ ~ $arr.length-1$为大于$num$的区域;初始为 $arr.length$;
graph TD
A[开始] -->B(less初始值为-1)
A -->F(cur初始值为0)
A -->G(more初始值为arr.length)
F -->I{cur是否小于more}
G -->I
B --> I
C{判断arr的cur上的值} -->|小于num| D[cur位置和less+1位置交换 less+=1]
C -->|等于num| H[cur= cur+1]
C -->|大于num| E[cur位置和more-1位置交换 more-=1]
D --> H
H --> I
E --> I
I -->|是| C
I -->|否| J[结束 返回less+1,more-1]
要考虑一下一些情况:
如果等于区域不存在
小于区域不存在
大于区域不存在
小于等于区域不存在
大于等于区域不存在
小于大于不存在(全是等于)
经典快速排序
原始经典快速排序;
荷兰国旗问题来改进;
经典快排的问题
划分出来的区域不是等规模的:特别在差不多有序情况下进行经典快排则会导致$O(N^2)$;本质上和数据状况是有关系的;
随机快速排序
随机快速排序的细节和复杂度分析
和经典快排不同的地方在于选择partition的num值;经典快排都是选择一个确定位置的值(第一个值或者最后一个值)来对整个数组进行划分;而这样就和数据状况存在关系。所以随机快速排序随机选择划分整个过程的num值。虽然这样选择的值也可能出现划分出来的区域不是等规模的。但是这只是一个概率事件,我们不能得知其时间复杂度的最差情况;只能用长期期望的方式算出它的时间复杂度。我们长期期望得到的时间复杂度为:$O(N*log N)$;
随机快速排序的组成
主函数:输入一个要排序的数组
1
2
3
4
5
6/*
快排主函数:
先判断数组需不需要排序
然后对 0 ~ arr.length-1 区间里调用2函数
*/
public static void quickSort(int[] arr)对区间里进行快速排序
1
2
3
4
5
6
7
8/*
如果左边界小于右边界
在数组中随机选一个数作为分割数num,将其交换到l最后一个位置去
按上一步找的数用 3 partition 把数组分为三部分:[小于num的,等于num的,大于num的],返回 [等于num的] 的边界,方便后两步
对 [小于num的] 执行快速排序
对 [大于num的] 执行快速排序
*/
public static void quickSort(int[] arr, int l, int r)分割数组
1
2
3
4
5
6
7
8
9
10
11
12/*
partition需要 less = l-1记录小于num的区域的边界,more = r记录大于num区域的边界 cur=l arr[r]保存着分割数num
这个思想与框图里的一样:
【l~less:小于num的区域, less+1~cur-1:等于num的区域, cur~more-1:未分类的区域, more~r-1:大于num的区域】
只要未分类的区域还存在循环不停止:
如果arr[cur] < arr[r]:要把它换到小于区域的下一个,而这个值是等于num区域的值;交换 ++less 和 cur++;
如果arr[cur] > arr[r]:把他换到大于区域前一个,交换过来的这个是未知区域的值;则要继续对cur位置做判断;
如果arr[cur] = arr[r]:当前数要划分进等于num的区域,直接cur++;
直接结束,交换more与r位置的数;
返回:[less+1, more]
*/
public static int[] partition(int[] arr, int l, int r)
规避数据状况对算法的影响的方法
- 随机
- 哈希函数
时间复杂度$O(N*log N)$,额外空间复杂度$O(log N)$
空间复杂度为什么是$O(log N)$?为了记录大于num和小于num的位置,并且需要递归记录。所以额外的空间承了一颗二叉树一样得。所以是$O(log N)$
题外话:任何递归函数都可以改写为非递归函数;
递归函数的压栈是对函数进行压栈,消耗的常数级空间和资源都比较大。并且系统栈是有限的,深度递归会造成不安全。
堆排序
堆的表示
堆的数据结构:完全二叉树
物理表示:一个数组,分为以0位置为根节点和以1位置为根节点两种表示方式;
以0位置为根节点:
i位置的左孩子:$2*i+1$ 右孩子:$2*i+2$;
i位置的父节点: $\frac{i-1}{2}$
以1位置为根节点:
i位置的左孩子:$2*i$ 右孩子:$2*i+1$
i位置的父节点:$\frac{i}{2}$
堆的分类
分为大顶堆和小顶堆
大根堆:在这个完全二叉树中任何一个子树的最大值都在子树的根上。
小根堆:在这个完全二叉树中任何一个子树的最小值都在子树的根上。
建立堆
以大顶堆为例;
思想:给定一个数组把它构建为一个大顶堆;
1 | 宏观:我们认为0 ~ i-1间已构成大顶堆,然后插入第i个数;i初始值为0,不断插入堆中,不断增长,一直到N-1; |
1 | for (int i = 0; i <arr.length ; i++) { |
tip:这里看到左神代码,可以符合i没有父节点和大于父节点两种情况的判断
1 | // 判断i位置和其父节点 |
经过验证java中的整除除法的整除,如果是负值则会往比较大的方向贴
1 | -1 / 4 : 0 |
而python不同:
1 | -1 // 4 : -1 |
插入堆(heapinsert)
1 | public static void heapInsert(int[] arr, int index) |
插入堆就是要不停的与父节点进行比较。如果大于就交换,小于则停止;
调整堆(heapify)
1 | public static void heapify(int[] arr, int index, int size) |
大顶堆中的一个数变小了,要对这样的情况进行调整;把它与他的两个子节点进行比较;如果大于它的左右节点那么就不调整了,如果小于就与较大的子节点进行交换。直到其大于他的左右子节点。当然结束条件不仅仅是大于两个子节点,也有子节点越界的情况。
已知:堆数组arr,调整数的下标 index,堆大小 heapsize
graph TD
A[开始] -->B[左节点下标 left = index * 2 + 1]
B --> C{left < heapsize}
C -->|yes|D[获得左右节点的较大值]
C -->|no|E[结束]
D -->F{index大于子节点}
F -->|yes|G
G -->E
F -->|no|H
H -->I[交换子节点较大值与index]
I -->J[index=较大值]
J -->B
堆的使用
例一:一个数据流不停的输出数;求当前输出数字的中位数;
分析:请求中位数是随时可能出现的;所以用普通线性容器对其进行排序所需的时间复杂度很高。
所以用堆来实现这个过程就很方便:
题解:
需要:一个大根堆存放较小的$\frac{N}{2}$个数;用大根堆把他们的最大值放在根部;
一个小根堆存放较大的$\frac{N}{2}$个数;用小根堆把他们的最小值放在根部;
大根堆和小根堆中元素的个数差不超过1;
分析:当大根堆和小根堆元素个数相同时:中位数为两个堆顶部元素的均方;
当大根堆和小根堆元素个数差1时:中位数为元素较多所在堆的根部;
维护堆:
初始:把元素加入进大顶堆;
插入元素:
a. 判断插入元素是否小于大顶堆根部,如果是则插入大顶堆,否则插入小顶堆
b. 再判断大顶堆和小顶堆元素个数的差;如果大于1,则弹出元素数较大的堆的根,再插入元素数较小的堆中;使其平衡;
堆排序
graph TD
A[开始] --> B{数组大小大于1}
B -->|是|H[构建堆]
H -->C[将堆中最后一个数与根交换]
C --> D[堆大小减1]
D --> F{堆大小不为空}
F --> |是|E[调整堆做一次heapify]
E -->C
F --> |否|G
B -->|否| G[排序完成]
排序算法的稳定性及其汇总
稳定性:相同的值经过排序之后他们在序列中的相对顺序会不会被打乱;不被打乱就是稳定的;
冒泡排序:可以实现稳定,大数沉底,但是遇到相等的时候不交换就可以实现稳定;
插入排序:可以实现稳定;从后往前插入,遇到相等的就停止。
选择排序:不是稳定的;需要与i位置往后最小值交换,使得其相对顺序会变化;
归并排序:可以实现稳定;元素相等情况下,先把左边数组的相等值优先拷贝进辅助数组,再拷贝右边数组的相等值;
快速排序:不是稳定的;partition的过程也有随机交换的地方;
堆排序:不是稳定的;
稳定性有什么意义? 现实世界有可能需要保证他的原始顺序;
工程中的综合排序算法
工程中使用的排序算法则不是利用某种排序算法,它是一个综合考虑各种情况各种排序算法优劣的算法;
如果需要排序的数组长度很长
先判断里面装的是基础类型,还是自定义类型?因为基础类型不需要考虑稳定性;
- 基础类型:用快排
- 自定义类型:归并排序
数组长度很短则直接用插入排序;因为插入排序所需的常数项操作很低。
有关排序问题的补充
- 归并排序所需的时间复杂度
O(n)的可以变成O(1)的,可以学习:“ 归并排序 内部缓存法 ”;非常难; - 快速排序可以做到稳定性,可以学习:“ 01 stable sort ”;非常难;
认识比较器的使用
Arrays.sort 里有一个比较器接口:
1 | public static void sort(T[] a,int fromIndex,int toIndex, Comparator c) |
通过自定义比较类型的比较器可以实现
1 | public static class IdAscendingComparator implements Comparator<T>{ |
因为自定义类型不告诉排序函数它用什么比较器,那么排序函数就会用内存地址对他们进行比较;
同样的java里还有优先队列;优先队列也就是一个堆;堆是大顶堆还是小顶堆都是需要用比较器来说明的;
1 | PriorityQueue<Student> heap = new PriorityQueue<>(new IdAscendingComparator()); |
还有TreeSet<Student> treeset = new TreeSet<>(new IdAscendingComparator());
桶排序、计数排序、基数排序
【例】一串数字,他们都是0~60范围里的数。要对这串数字进行排序;
可以实现一个数组用来统计相应位置上的数出现的个数。在利用整个数组得到排序后的结果;
而这里数组中的 i 位置保存数字 i 的个数。这就是一个桶;
桶保存了一种数据状况出现的词频,是容器;
桶排序
而桶排序是一种思想,它不是具体的某一个排序算法。而基数排序与计数排序都是对它的具体实现;
但是可以看到这种排序是有局限性的,它的使用与数据状况关联很大;
计数排序要求被排序的数字在某一个范围里面;不然的话所需的范围极大,所需的桶也极多。这是它不好的地方;
补充问题
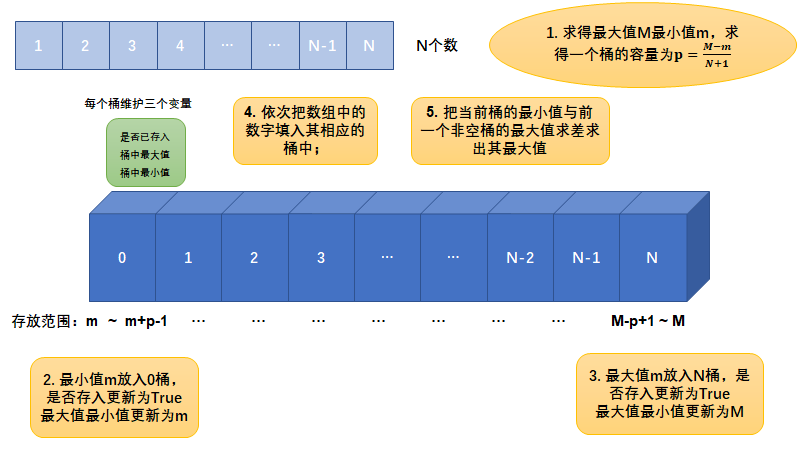
给定一个数组,求如果排序之后,相邻两数的最大差值,要求时 间复杂度O(N),且要求不能用非基于比较的排序。
step-1 : 排序数组有N个数,那么准备N+1个桶
step-2 : 遍历整个数组找到其最大值与最小值
step-3 : 如果最大值与最小值相等则说明数组中都是一样的数,就直接返回0;
step-4 : 如果不相等则分别把最小值放在0号桶里,把最大值放在N号桶里。
step-5 : 把桶按最小值与最大值之间的范围等分为N+1份
分析:
设一个桶能装的范围是p,它是由 $\frac{最大值 - 最小值}{N-1}$ 计算而来
由于有N个数放进N+1个桶里。那么起码会出现一个空桶;
相邻的两个数会出现在两个地方:在同一个桶里,在不同的桶里;
相邻的两个数在一个桶里他们的差值不会大于桶的范围:$(1, p-1)$;
两个数在相邻两个桶,他们的差值范围在 $(1, 2*p-1)$;
而两个数中间有一个空桶的相邻数一定大于桶的范围 $(p+1, 3p-1)$;
因为起码会出现一个空桶,所以相邻数的差的最大值不会出现在同一个桶里。所以只需要查看桶之间的差值就好了。
对这个过程进行完整的描述:
step-1 : 排序数组有N个数,那么准备N+1个桶;这个桶只保存有没有进来过数,进来数中最大值,最小值,这三样信息;
step-2 : 遍历整个数组找到其最大值与最小值
step-3 : 如果最大值与最小值相等则说明数组中都是一样的数,就直接返回0;
step-4 : 如果不相等则分别用最小值更新0号桶布尔值,最大值和最小值,用最大值更新N号桶的布尔值,最大值和最小值。
step-5 : 然后依次把数组中的数字填入相对应的桶中;
step-6 : 对桶进行遍历,依次比较当前桶的最小值与上一个非空桶最大值的差,找到其中最大的值;